




- Взгляд на последовательности ResultSets
- Взгляд на код
- Советы по проблемам производительности и JDBC-драйверов
- Заключение
- Дополнительные ресурсы
- Часть 1
Даже не смотря на то, что вы умеете создавать сложные приложения, пользуясь простыми и лёгкими в применении моделями построения JDBC API, добиться более продуктивной работы своего приложения вы сможете, если дадите возможность утверждению (single statement) возвращать последовательность ResultSets. В этой статье автор объясняет методику использования механизмов получения сразу нескольких объектов ResultSet.
Природа взаимодействия Java-приложения и реляционной базы данных остаётся всегда одной и той же, поскольку модуль приложения, осуществляющий это взаимодействие с базой, выполняет одни и те же операции. В большинстве случаев этот модуль также выполняет и большую часть операций по получению или введению данных в том же порядке, что другие JDBC-драйверы для баз данных. И пока внутри самой базы данных не будет создана такая прикладная система (с помощью компилируемых базой процедур хранения для выполнения всех функций), вы должны будете создать Statement нескольких параллельных SQL-запросов или утверждений (statements) для получения нескольких ResultSets одновременно. Независимо от того, будет ли прикладная система использовать компилируемые базой процедуры хранения, способы получения вами объектов ResultSet будут варьироваться, в зависимости от возможностей базы данных и её JDBC-драйвера. Вы можете использовать все модели, описываемые в этой статье для JDBC версий 1.22 и 2.0.Два наиболее очевидных сценария получения последовательности ResultSets из базы данных, т.е. сценарий для последовательности SQL-запросов и второй сценарий - CallableStatement для нескольких ResultSet. Оба сценария должны будут работать с любой базой данных, которая способна работать с большими приложениями масштаба предприятия, поскольку для их поддержки здесь используется JDBC API. В качестве уточнения стоит заметить, что под базой данных масштаба предприятия подразумевается база, способная обрабатывать компилируемые процедуры хранения.
|
Сценарий
|
Описание
|
Диаграмма сценария
|
| Последова- тельность SQL-запросов |
Создать Statement (или Prepared Statement) из открытой Connection с базой данных. Передать последовательность SQL-запросов в Statement и получить ResultSet с логическим отображением из базы данных. |
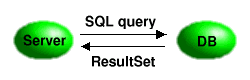 |
| Callable Statement multiple ResultSet | Создать Callable Statement из открытой Connection с базой данных. Передать процедурный SQL-вызов (выполнив Stored Procedure) в CallableStatement и получить последовательность ResultSets. |
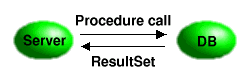 |
Взгляд на последовательности ResultSets
Теория обработки одновременно нескольких ResultSets достаточно проста. Драйвер базы данных обрабатывает набор ResultSets вместо каждого отдельного ResultSet, как вы привыкли. Таким образом, логическая (упрощённая) структура, возвращаемая вызовом базы данных либо из сценария для последовательности SQL-запросов, либо из сценария для CallableStatement нескольких ResultSet, может рассматриваться как java.util.List. Элементами такого списка (List) являются возвращаемыми базой данных ResultSets как реакции на SQL-запрос.
Рисунок 1. Последовательность ResultSets в виде списка
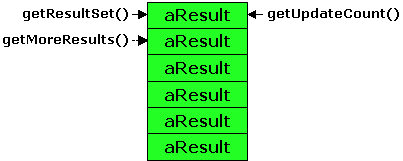
Вы можете доставать текущий элемент списка результатов, используя метод getResultSet() или getUpdateCount(). В JDBC нет метода, который мог бы сказать вам, какой тип результата вы в данный момент рассматриваете (к примеру, объект ResultSet или примитивный updateCount int). Вместо этого оба getter-метода возвращают особые результаты (null или -1), чтобы подчеркнуть, что текущий результат может иметь непредсказуемый тип. Оба getter-метода возвращают особые результаты, когда добираются до конца списка результатов. Вы можете использовать метод getMoreResults() для перемещения ссылки на текущий результат вперёд в списке результатов базы данных. Обратите внимание на то, что метод getMoreResults() должен закрывать любой ResultSet, открытый ранее. Но я бы порекомендовал протестировать реализуемый JDBC-драйвер, прежде чем использовать его в этом случае.
Взгляд на код
Структура таблицы базы данных, используемая в коде вызовов JDBC, выглядит как обычная test-таблица, содержащая два столбца (id:integer и fname:varchar). Кроме таблицы ещё необходимы процедуры хранения. Процедура хранения просто выполняет два действия выбора в тестировочной таблице. Реализация процедуры хранения в TransactSQL-ориентированной базе данных (такой как Sybase или MS SQL Server) выглядит следующим образом:
CREATE PROCEDURE reverseSelectionProcedure
AS |
Структура всех кодовых примеров в данной статье соответствует одному шаблону: они наследуют весь функционал, за исключением метода main(), из класса MultipleResultsets. Метод main() реализован в каждом из подклассов в полной мере. Полный код исключения приводится только их желания продемонстрировать более элегантную модель построения (см. Ресурсы) для обеспечения удобства при чтении.
Рисунок 2. Сценарий использования нескольких ResultSets

Ниже приводится последовательность вызовов методов:
-
1. main() вызывает setupConnection(), который создаёт Logger
и возвращает установленную JDBC-связь с базой данных.
2. PreparedStatement создаётся из соответствующего SQL. Заметьте, что CallableStatement расширяет PreparedStatement.
3. processStatement() вызывается для распечатки данных о состоянии из данного PreparedStatement.
4. main() закрывает Statement из шага 2 и Connection из шага 1.
Первым идёт кодовая структура класса Logger:
import java.io.*; |
Общим для всех примеров суперклассом, используемым в данной статье, является MultipleResultsets, как показано ниже. Он обеспечивает две функции: установление связи с базой данных (включая загрузку драйверов) и обработку результатов всего PreparedStatement, содержащего SQL-запрос к базе данных.
Далее следует кодовая структура класса MultipleResultsets:
import java.sql.*; |
Два класса SimpleSQLMultipleResultsets и StoredProcedureMultipleResultsets расширяют MultipleResults и обеспечивают имплементацию основного метода, реализующего два описанных выше сценария. Класс SimpleSQLMultipleResultsets использует SQL-запрос, возвращающий из базы данных два ResultSets.
Так выглядит скелет кода сценария для последовательности SQL-запросов:
import java.sql.*; |
Во время выполнения SimpleSQLMultipleResultsets выдаёт следующий результат:
Time: 1999-12-10 12:27:27.784 |
При выполнении этой же операции с помощью компилируемой базой данных процедуры хранения reverseSelectionProcedure логика перемещается в базу данных, и Java-приложение начинает работать как информационный фильтр, абсорбируя все результаты, передаваемые базой. В таком случае вам тоже придётся использовать объект CallableStatement для инкапсулирования вызова к процедуре хранения базы данных. Ни каких других изменений в код вносить больше не нужно, поскольку интерфейс CallableStatement расширяет PreparedStatement.
Ниже приведен схематический код сценария CallableStatement multiple ResultSet:
import java.sql.*; |
Во время выполнения StoredProcedureMultipleResultsets выдаёт следующий результат:
Time: 1999-12-10 12:44:44.445 |
Советы по проблемам производительности и JDBC-драйверов
Хорошая реализация JDBC-драйвера является ключевым средством достижения хорошей производительности при работе с базами данных. В зависимости от того, насколько умело база данных и JDBC-драйвер используют кэширование и насколько это кэширование полезно для процедуры хранения, будет зависеть простота интерпретации результатов тестирования производительности. Наиболее эффективным будет использование кэша для менее сложных задач. Поэтому я бы рекомендовал не использовать настолько простые процедуры хранения как reverseSelectionProcedure, показанная выше. Если вы решите, что воспользоваться строкой SQL-утверждения не сложнее чем той, что была выполнена reverseSelectionProcedure, вы можете добиться более высоких результатов с помощью PreparedStatement.
Нужно отметить, что некоторые JDBC-драйверы требуют предварительной проверки на способность возвращать последовательность ResultSets. В некоторых случаях драйверы просто в тихоря игнорируют второй ResultSet из утверждения. Поэтому, прежде чем использовать какой-либо драйвер в своей системе, лучше его протестировать.
Заключение
Сокращение количества сетевых или внутрипроцессорных обращений к базе данных для получения информации позволяет значительно повысить скорость прикладной системы. Использование средств пакетной обработки транзакций (обеспечиваемых в JDBC 2.0 API) повышает производительность и обеспечивает изолированность пользователя базы данных. В сочетании с возможностью получения нескольких ResultSets одновременно в соответствии со сценарием для последовательности SQL-запросов или CallableStatement multiple ResultSet, это позволит вам ещё больше сократить время обращения к базе данных. Если это возможно, то такие средства должны в полной мере использоваться серверными приложениями масштаба предприятия.
Дополнительные ресурсы (на английском языке)
- Design Patterns: Elements of Reusable Object-Oriented Software, Erich Gamma (Addison-Wesley, 1994), приводится информация об abstract factory patterns
- Sun's JDBC site
- JDBC information from Oracle
- JDBC information from Informix
- JDBC information from Sybase
<< НАЗАД